Stuff Needs to Build
gnumake
... this is a work in progress ...
Upcoming sections:
- Implementing the build process
- Creating and maintaining builds
- Creating from bottom up
- mvmake.mk (3 running example: .exe, lib w/ subdirs, 3rd
party XMLlib
- Testing the build
- Using the build process
- Command line, batch file, and aliases
- Visual Studio integration
- Growing a build
- Adding rules for other languages/tools
- Increasing compiler warning levels
- Visual Studio integration
- Requirements Review
- gnumake notes
Building code should be as easy as drinking coffee. A software
developer is constantly building and rebuilding code throughout the
development and test process. The build must be easy and efficient.
It has to be so easy that it requires not thought since the
developer is typically building while actually concentrating on code
design and/or code debug. A complex build operation would destroy
this concentration, or worse execute incorrectly and add frustration.
Start a build, drink some more coffee: no thought.
Creating and maintaining the build must be as easy as learning
how to work the corporate coffee machine. Every developer needs to
be able to add source files and create new libraries with minimal,
often no, training. This new work must also be communicated. The
developer is extending the build. Either the developer has to
personally communicate the extension to all other build users, or
better, the extension should automatically transfer the changes into
other developers' builds. The second is preferable since it does
not require developer-to-developer communications. It is much like
having the next developer walk up to the coffee machine and simply
find coffee in the pot.
Developers, like coffee drinkers, are all different. In the end,
the code is built and the coffee is in the stomach. It is the path
to that end that varies. I was once part of a development team
where at least four of the seven members had completely unique
habits of writing and building code. I wrote code using emacs and
built within the Korn shell on a Windows NT platform. Another
developer did everything within Microsoft's Visual Studio. A third
developer wrote code using CodeWright and built with the NT command
prompt. The fourth developer used his Windows 95 laptop as an
intelligent terminal to a Solaris box. He edited in VI on the
Solaris and compiled using the C shell. All four of us were coding
to the same project. We shared the same code and build. A single,
good build process easily handled all these developer environments.
The build, like the coffee, had to work cleanly for all of us
(especially late at night when we were tired).
The coffee and coffee machine metaphor sounds nice, even easy.
Unfortunately, the secondary issues related to building code can
become quite complex. The coffee metaphor only holds for one or a
few developers building code in their personal development
environments. There could be multiple, different delivery
environments, e.g. Linux and Windows. The build might also need to
survive customer use when APIs or open source are appropriate. The
choice is whether to deal with the complexity of issues up
front, or ignore them until the issues come crashing in later.
Cost of ignoring issues
A build, simply stated, transforms human readable programming
into a machine executable form. I believe every build I have ever
seen succeeds in this basic task. The poor builds fail to address
other issues that do not arise until later in the project's or
company's evolution. Some of the commonly ignored issues are:
- automated builds and automated nightly testing,
- multiple environments (e.g. Windows, Linux, Solaris),
- third-party sources and builds,
- multiple testing and debugging derivative builds,
- multiple users: developers, customers, QA and release staff, and
- scaling beyond 6, even 20 independent library builds for a
single executable.
The horror stories that resulted from these ignored issues are
numerous, and costly:
A developer was asked to establish nightly builds and test
runs. None of the two dozen modules built in a similar fashion,
and had other developers regularly changing module build methods.
This developer, after losing much hair to frustration, finally
created an independent build method to feed the nightly tests.
The other developers soon ignored the nightly test reports since
most of the errors had to do with improper builds. That nightly
build and test effort was subsequently abandoned.
An internet firm used a third-party library to assist in
making their code portable. Somehow the build was not portable,
even though the code was. This company had six developers
supported by six release engineers that massaged the builds. Yes,
they went out of business.
The openssl shareware is an extensive library package that takes
a long time to build. A development group never figured out how
to keep the library from rebuilding every time the full build was
started. So many an engineer watched and waited while this
unchanging code rebuilt for no reason. In some situations, the
library rebuilt twice during a single build execution.
I was regularly plagued by an issue with Microsoft Visual
Studio. Visual Studio will properly recompile appropriate source
files when any .h/include file that it knows about changes.
Telling it about every .h/include can be a nightmare when you are dealing with large sets of libraries that are maintained/changed
by multiple developers. If you do not manually tell it about
every .h/include file, sometimes Visual Studio does not recompile
sources that really need it. More than once I spent minutes,
maybe hours, hunting down weird bugs that resulted from this.
Worse, I often rebuilt all the sources just in case a bug might be
from a missing compile. So the Visual Studio problem hurt my
productivity both when it properly compiled and when it did not
fully compile since I just did not trust it.
A piece of telephony software leaked 2K of memory per phone
call. This leak was catastrophic since the software was used in a
telephone support center that never rebooted machines. After four
days, various machines started faulting with "No virtual memory"
errors. The memory leak test code was free and easily
activated. The developers just never took time to activate the
code during development builds. Similarly, some really horrible
logging code would have immediately been changed if anyone had
activated the profiling code just once. These two tools could
easily have been managed in a good build process.
A manager once confided that he was embarrassed to train new
employees. He would recruit them with promises of opportunities
to work with industry's brightest and to work on state of the art
code. Then on their first day of work, he had to show them how to
build the code. There was no way to set up the build for one
executable. First, a developer had to build the entire source
tree (a twenty to forty minute wait) on a designated build
machine. Only one person could use the build machine at a time,
and it was possible for two people to overlay each other's builds
without knowing it. Once the new developer got to work on the
target executable, each incremental compile might again require
the build machine (which again might be "corrupted" by someone
else's work on a different executable). Worse, the developer's
personal workstation was more powerful than the build machine that
was shared by a thirty plus developers.
None of the individuals involved with these horror stories were stupid.
They were just so occupied elsewhere that clean and efficient
resolution to the issues was not the solution chosen. Throwing more
people at the problem and/or living with the inefficiencies was the chosen
solution.
I compare these horror stories to having a coffee machine without
a coffee pot. Each person would start the coffee machine and walk
away when their cup was full. The fact that the machine continued
to produce a pot's worth of coffee for the carpet's consumption was
not important. Let the cleaning folks deal with the problem instead
of ordering a new coffee pot.
Requirements and tools
This build process implementation is exceedingly simple even
though the requirements placed upon it are exceedingly large. Once
in operation, it really is as easy to use as a coffee mug. It is
also as easy to maintain as making a pot of coffee. The
requirements list that follows restates most of the issues from the
introduction:
- build files are uniform across all modules so as to support build/test
automation and to create clear developer to developer communication,
- same build files used in native environment of Windows
(command.exe, cmd.exe, or ksh.exe) and Linux (bash),
- a build for one module automatically builds all dependent
libraries (and recursively builds any dependent libraries of the
dependent libraries),
- 3rd party libraries also built by the process,
- global build capability extensions possible through single
point of change for all modules (e.g. debug builds, profile
builds),
- build process automatically creates include file
dependencies and uses them, and
- when execute twice in succession, the build does nothing the
second time, returning to the user immediately.
Some secondary requirements that are also achieved:
- the build structure allows multiprocessor (SMP)
builds,
- the build structure minimizes, if not eliminate,
operating system dependent ifdef's, and
- typical subdirectory layouts are easily interfaced.
Three key tools are necessary to achieve the requirements:
gnumake (Windows and Linux versions), a pair of make file templates,
and a dependency generator for Windows implementations.
gnumake version 3.79 is readily available for
many operating environments. Version 3.77 is widely distributed but
has several nasty bugs. One of 3.77's bugs can render this make
setup useless when faced with deeply nested subdirectory paths.
Please upgrade to 3.79 or better.
A pair of make file templates feed information to gnumake for
this build process. One template, mvmake.mk, must exist in each
module directory and be customized for that module. There is only
one copy of the second template, basemake.mk. It contains generic
rules and macros that integrate all mvmake.mk files at build time.
Complete copies of the templates are found in the appendix and
online
(mvmake.mk and
basemake.mk).
The Windows dependency generator extracts the list of include
files found by the Microsoft preprocessor for use by gnumake.
gnumake needs this information to be able to accurately determine
which sources need to build after any one file anywhere in the build
subdirectories changes. This dependency information is also stored
within Microsoft's .idb files. However, there is no published interface
to the .idb files. This build process extracts the information by
re-running the preprocessor and reformats the information for
gnumake via the mvdeps.exe tool.
Build process
gnumake orchestrates the entire build process based upon the
input files provided. Conceptually, gnumake executes the build in
three phases. No, the gnumake program does not execute exactly in
this phased order. It actually operates in a more recursive fashion
that fully or partially executes all three phases as it reads each
file. I present the process as three phases because it is much simpler to
communicate the concept. The final results of gnumake and this
discussion appear the same to the developer. The key is to
understand these contrived phases in order to understand how the
build process works.
The phases are:
- Load all input files (mvmake.mk, basemake.mk, .d files)
- Create internal file dependency trees with separate variable names by module
- Execute build commands for all out of date files
gnumake phase I
This phase starts in the directory of the desired module. The
mvmake.mk in the current directory defines the other modules
it uses. It also specifies that gnumake read basemake.mk (which is
always in a directory named mevlib). basemake.mk instructs gnumake
to load the mkmake.mk for each of the modules specified by the
initial mkmake.mk and any subsequent modules specified by these
mkmake.mk's. So at minimum gnumake has to process two files, the
initial mvmake.mk and basemake.mk. It could end up processing
dozens of mvmake.mk files if that many modules are defined in the
mvmake.mk files.
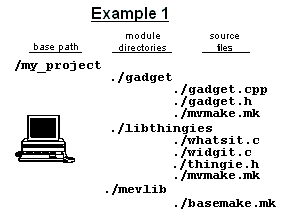 In Example 1, ./gadget is the current directory. The command
"
In Example 1, ./gadget is the current directory. The command
"gnumake -f mvmake.mk" starts gnumake with
gadget/mvmake.mk as the first input file. This initial mvmake.mk
sets a variable ($M/MODULES_NEEDED) with the name of
the modules it needs for compiling/linking. In this example,
gadget/mvmake.mk needs the libthingies module so it contains the
line:
$M/MODULES_NEEDED := libthingies
$M/MODULES_NEEDED and informs gnumake to load
libthingies/mvmake.mk also. This example uses three make files:
gadget/mvmake.mk, libthingies/mvmake.mk, and basemake.mk.
Developers maintain the mvmake.mk files. The build process design
minimizes the amount of information contained in these files so the
developer can focus on the project, not the build. Developers must
take each of the modules main deliverables (executables, libraries,
etc.) and map those to their major source files. Developers do not
need to map all of the secondary source files (include files) that
the major source files use. The mvmake.mk and basemake.mk files
contain information that allows gnumake to create and maintain a
series of dependency files that end with ".d". These dependency
files list all the secondary source files and their relation to each
major source file. basemake.mk also instructs gnumake to also load
the dependency files during this first phase of build processing.
So basemake.mk and gnumake are automatically maintaining the
secondary to major source file dependency lists. The developer does
not have to worry about all the secondary source files that might be
changing in other modules.
 Example 1a shows the dependency files that the build process adds
within the module directories. There is one .d file for each of the
major source files. basemake.mk contains the instructions gnumake
uses to create and maintain these files. gnumake builds the .d
dependency files during Phase I processing.
Example 1a shows the dependency files that the build process adds
within the module directories. There is one .d file for each of the
major source files. basemake.mk contains the instructions gnumake
uses to create and maintain these files. gnumake builds the .d
dependency files during Phase I processing.
The dependency files establish a relationship between major
source files and every source file that is subsequently included
during compiler preprocessing. The Unix compiler gcc has an option
that causes its preprocessor to output a list of these included
source files. basemake.mk uses this compiler option to create
dependency files on a Linux platform. Microsoft's compiler has a
similar feature, but the information is stored in a proprietary
format. basemake.mk has to use alternate compiler options and the
mvdeps.exe tool to create dependency files on a Windows
platform.
gnumake phase II
The second phase of gnumake's processing builds a series of data
trees. There is a tree for file name relationships and a tree for
variable namespaces. gnumake populates these data trees based upon
three major grammatical constructs in the input files (mvmake.mk,
basemake.mk, and .d files).
-
The "Rule" construct defines the relationship between source
files and built files. The construct has two variants:
- Variant 1
target : prerequisites
- Variant 2
target : prerequisites
command(s)
Variant 1 only defines a relationship between the target file
(built file) and one or more prerequisites (source files). This
variant assumes that default commands exist elsewhere. This build
process has most of the default commands defined within
basemake.mk. This is the preferred variant since the build commands
are centralized and more easily extended for all modules.
Variant 2 is like Variant 1 in that it defines a relationship
between the target and its prerequisites. This variant also give
the commands that gnumake should execute whenever the change date of
any prerequisite is more recent than the target or when the target
does not exist. This variant should only be used for targets that
are especially unique amongst the modules in how they are built.
However if there is one unique target today, there will most likely
be another in the future. The better choice is probably to still
use variant 1 and add the special build rules generically to basemake.mk.
The data tree for this construct is fairly simple. Each target
is a node in the file name tree. The node points to a list of file
names that are its prerequisites. Any of the prerequisite file
names could also be listed as targets somewhere in the input files.
Each file name node has its change date as an attribute. The node
may also have explicit commands for constructing it if it is defined
by a variant 2 rule.

Example 1b shows the data tree describing the example build (.exe
is the Windows file extension for an executable, and .lib is the
extension for a static library). gnumake will execute the commands
to build gadget.exe whenever it detects that one or more of its
prerequisite files (gadget.cpp, gadget.h, libthingies.lib, or
thingie.h) has a more recent change date. Notice that
libthingies.lib also has prerequisites. gnumake must also check
libthingies' prerequisites to determine if it should be built.
Should libthingies build because of its prerequisites, the change
time of the new libthingies is used for gadget.exe's date test.
The example shows thingie.h in two places. Within the actual
data tree there is only one thingie.h node. Each prerequisite list
uses this same file name node.
-
gnumake supports the use of variables within the rules. All
variable values are basically strings. The variable values can
contain lists of file names, compiler options, and even other
variables. There are two assignment operators that determine when
gnumake expands any variables that are within a string. This
difference in embedded variable expansion is extremely
important.
- Immediate expansion (a.k.a. simply expanded)
variable := string
- Deferred expansion (a.k.a. recursively expanded)
variable = string
Immediate versus deferred expansion becomes an attribute of the
variable. This attribute impacts how the string value parses during
assignment and how the variable parses when subsequently used.
Immediate expansion causes any variables in the string value to
be fully expanded at the moment gnumake parses the assignment
statement. Anytime gnumake sees an immediate expansion variable
while parsing the input files, it immediately substitutes the
current value of the variable. Equivalent descriptions of immediate
expansion are "variable expansion/substitution occurs during Phase
II processing" and "variable substitution occurs at parse time".
Deferred expansion causes any deferred variables in the
string value to be saved as the variable name. No substitution
of their value occurs during assignment. These variables only
expand when assigned to immediate expansion variable, or more
commonly when gnumake actually executes a rule's command that uses
them. Rule commands only expand during Phase III processing.
The rule construct resolves variables into its data tree
in the following fashion:
target (immediate) : prerequisites (immediate)
commands (deferred)
Example 2 illustrates a series of lines in a gnumake input file.
Each row in Example 2 represents an incremental parsing of an input
line. The first column is the line parsed. The second column shows
the impact of that line on the variable data tree. The third column
shows the impact of the variables upon parsed rules.
| Example 2 |
|---|
| # |
line in source file |
variable data tree |
file data tree |
| 1 |
defer1 = aaa.c |
defer1 (deferred) "aaa.c" |
| 2 |
defer2 = $(defer1) |
defer1 (deferred) "aaa.c"
defer2 (deferred) "$(defer1)" |
| 3 |
immed1 := $(defer1) |
defer1 (deferred) "aaa.c"
defer2 (deferred) "$(defer1)"
immed1 (immediate) "aaa.c" |
| 4 |
defer1 = bbb.c |
defer1 (deferred) "bbb.c"
defer2 (deferred) "$(defer1)"
immed1 (immediate) "aaa.c" |
| 5 |
target.x : $(defer2)
compile $(defer1) $(immed1) |
defer1 (deferred) "bbb.c"
defer2 (deferred) "$(defer1)"
immed1 (immediate) "aaa.c" |
target.x : bbb.c
compile $(defer1) aaa.c |
| 6 |
immed1 := ddd.c |
defer1 (deferred) "bbb.c"
defer2 (deferred) "$(defer1)"
immed1 (immediate) "ddd.c" |
target.x : bbb.c
compile $(defer1) aaa.c |
| 7 |
defer1 = eee.c |
defer1 (deferred) "eee.c"
defer2 (deferred) "$(defer1)"
immed1 (immediate) "ddd.c" |
target.x : bbb.c
compile $(defer1) aaa.c |
| - |
gnumake executes target.x's command |
defer1 (deferred) "eee.c"
defer2 (deferred) "$(defer1)"
immed1 (immediate) "ddd.c" |
compile eee.c aaa.c |
There are a few notable items in Example 2. The variable data
tree after line 3 is parsed shows the difference between assigning a
deferred variable to another deferred variable versus assigning it
to an immediate variable. Line 5 shows two things. First it shows that
deferred variables are expanded to their values upon parsing.
Second it shows how the rule's command only expands the immediate
variable. This is because the command string is itself a deferred
value. Lines 7 and 8 show that the deferred variables can change
values after the command in line 5 is parsed and still impact the
command line that actually executes. Carefully walk the lines in
Example 2 to see when values do and do not change to better
understand deferred versus immediate variables.
-
mvmake.mk and basemake.mk heavily rely on the third construct.
This is the pattern specific variable construct. This construct
allows the same variable name to contain different values depending
upon the target that is currently being built. An alternate description
is that each target (pattern) can have its own set of variable
names, even if the variable names match those that other targets use. The
construct and an example are:
pattern_string% : assignment construct
/my_project/gadget/% : LIBS = libthingie
The pattern specific variable construct allows every mvmake.mk to
use the same variable names, but have different values in every
module (every mvmake.mk file). gnumake reads all mvmake.mk files
during Phase I and would otherwise parse the variables into the same
data tree. Only the last mvmake.mk read would have its commands
properly expanded.
gnumake phase III
The first action in Phase III is for gnumake to identify the
file name or names in the file data tree that must be tested and
potentially built. Either the developer specifies the file or files
on the command line, or gnumake selects the target of the first rule
it parsed in the input files. Developers typically do not specify
the final target directly. So every mvmake.mk contains a default
rule, "all : build" in the first few lines of the
file. The target "all" becomes the file name that
gnumake tests.
"all" and "build" are phony file names.
They exist in the rules, but have commands listed in any input as to
how to build them. gnumake assumes these phony files are older than
any real file. This assumption ensures that the analysis of the
file tree continues through the file data tree to real files. Any
and all of the real files list as prerequisites to
"build" in basemake.mk (and their prerequisites) will
be built if old or missing. The phony file names are a simple
method of reserving the default targets' definition to a later time
in the parsing.
 Example 1d shows how "
Example 1d shows how "all" and "build" fit
into the example file data tree from Example 1c. They fit before
gadget.exe. gnumake will attempt to see if "all" was
up to date. In comparing it to "build", it discovers
that it must test if gadget.exe is up to date before it can evaluate
"build". The process continues recursively as it must
now test the prerequisites of gadget.exe and each prerequisite's
prerequisite, etc. Once the recursion completes, along with any
builds necessary to get targets up to date with prerequisites,
gadget.exe is up to date. At this point, gnumake marks the
"all" and "build" file names as up to date
by default since they have no commands as part of their rule.
[need sidebar about recursive versus inclusive makes
... reference paper]
[need to show how to make generic build rules in basemake.mk]
[map design back to requirements]
[maybe put in paragraph as to why folks should read build phases
stuff: helps maintainers]
[maybe describe sections in terms of roles: user, maintainer, implementer]
Establishing standard directory layout
The build process, and in particular the make file templates,
require a very simple subdirectory tree.
gnu make 3.79 will not work properly if you chose to nest several
layers of builds within one module directory (several sub modules,
discussed later). This can be corrected by applying a patch to
rule.c of gnumake and recompiling. (Yes, this change was submitted
and rejected by gnu. Others have reviewed it and also believe it to
be appropriate.)
Copyright 2001, by Matthew Von-Maszewski
- $RCSfile: make.html,v $
- $Date: 2001/10/13 21:59:57 $
- $Revision: 1.19 $